Cowboy
Contents
Rationale
The modern Web
Cowboy is a server for the modern Web. This chapter explains what it means and details all the standards involved.
Cowboy supports all the standards listed in this document.
HTTP/2
HTTP/2 is the most efficient protocol for consuming Web services. It enables clients to keep a connection open for long periods of time; to send requests concurrently; to reduce the size of requests through HTTP headers compression; and more. The protocol is binary, greatly reducing the resources needed to parse it.
HTTP/2 also enables the server to push messages to the client. This can be used for various purposes, including the sending of related resources before the client requests them, in an effort to reduce latency. This can also be used to enable bidirectional communication.
Cowboy provides transparent support for HTTP/2. Clients that know it can use it; others fall back to HTTP/1.1 automatically.
HTTP/2 is compatible with the HTTP/1.1 semantics.
HTTP/2 is defined by RFC 7540 and RFC 7541.
HTTP/1.1
HTTP/1.1 is the previous version of the HTTP protocol. The protocol itself is text-based and suffers from numerous issues and limitations. In particular it is not possible to execute requests concurrently (though pipelining is sometimes possible), and it's also sometimes difficult to detect that a client disconnected.
HTTP/1.1 does provide very good semantics for interacting with Web services. It defines the standard methods, headers and status codes used by HTTP/1.1 and HTTP/2 clients and servers.
HTTP/1.1 also defines compatibility with an older version of the protocol, HTTP/1.0, which was never really standardized across implementations.
The core of HTTP/1.1 is defined by RFC 7230, RFC 7231, RFC 7232, RFC 7233, RFC 7234 and RFC 7235. Numerous RFCs and other specifications exist defining additional HTTP methods, status codes, headers or semantics.
Websocket
Websocket is a protocol built on top of HTTP/1.1 that provides a two-ways communication channel between the client and the server. Communication is asynchronous and can occur concurrently.
It consists of a Javascript object allowing setting up a Websocket connection to the server, and a binary based protocol for sending data to the server or the client.
Websocket connections can transfer either UTF-8 encoded text data or binary data. The protocol also includes support for implementing a ping/pong mechanism, allowing the server and the client to have more confidence that the connection is still alive.
A Websocket connection can be used to transfer any kind of data, small or big, text or binary. Because of this Websocket is sometimes used for communication between systems.
Websocket messages have no semantics on their own. Websocket is closer to TCP in that aspect, and requires you to design and implement your own protocol on top of it; or adapt an existing protocol to Websocket.
Cowboy provides an interface known as Websocket handlers that gives complete control over a Websocket connection.
The Websocket protocol is defined by RFC 6455.
Long-lived requests
Cowboy provides an interface that can be used to support long-polling or to stream large amounts of data reliably, including using Server-Sent Events.
Long-polling is a mechanism in which the client performs a request which may not be immediately answered by the server. It allows clients to request resources that may not currently exist, but are expected to be created soon, and which will be returned as soon as they are.
Long-polling is essentially a hack, but it is widely used to overcome limitations on older clients and servers.
Server-Sent Events is a small protocol defined as a media type, text/event-stream, along with a new HTTP header, Last-Event-ID. It is defined in the EventSource W3C specification.
Cowboy provides an interface known as loop handlers that facilitates the implementation of long-polling or stream mechanisms. It works regardless of the underlying protocol.
REST
REST, or REpresentational State Transfer, is a style of architecture for loosely connected distributed systems. It can easily be implemented on top of HTTP.
REST is essentially a set of constraints to be followed. Many of these constraints are purely architectural and solved by simply using HTTP. Some constraints must be explicitly followed by the developer.
Cowboy provides an interface known as REST handlers that simplifies the implementation of a REST API on top of the HTTP protocol.
Erlang and the Web
Erlang is the ideal platform for writing Web applications. Its features are a perfect match for the requirements of modern Web applications.
The Web is concurrent
When you access a website there is little concurrency involved. A few connections are opened and requests are sent through these connections. Then the web page is displayed on your screen. Your browser will only open up to 4 or 8 connections to the server, depending on your settings. This isn't much.
But think about it. You are not the only one accessing the server at the same time. There can be hundreds, if not thousands, if not millions of connections to the same server at the same time.
Even today a lot of systems used in production haven't solved the C10K problem (ten thousand concurrent connections). And the ones who did are trying hard to get to the next step, C100K, and are pretty far from it.
Erlang meanwhile has no problem handling millions of connections. At the time of writing there are application servers written in Erlang that can handle more than two million connections on a single server in a real production application, with spare memory and CPU!
The Web is concurrent, and Erlang is a language designed for concurrency, so it is a perfect match.
Of course, various platforms need to scale beyond a few million connections. This is where Erlang's built-in distribution mechanisms come in. If one server isn't enough, add more! Erlang allows you to use the same code for talking to local processes or to processes in other parts of your cluster, which means you can scale very quickly if the need arises.
The Web has large userbases, and the Erlang platform was designed to work in a distributed setting, so it is a perfect match.
Or is it? Surely you can find solutions to handle that many concurrent connections with your favorite language... But all these solutions will break down in the next few years. Why? Firstly because servers don't get any more powerful, they instead get a lot more cores and memory. This is only useful if your application can use them properly, and Erlang is light-years away from anything else in that area. Secondly, today your computer and your phone are online, tomorrow your watch, goggles, bike, car, fridge and tons of other devices will also connect to various applications on the Internet.
Only Erlang is prepared to deal with what's coming.
The Web is soft real time
What does soft real time mean, you ask? It means we want the operations done as quickly as possible, and in the case of web applications, it means we want the data propagated fast.
In comparison, hard real time has a similar meaning, but also has a hard time constraint, for example an operation needs to be done in under N milliseconds otherwise the system fails entirely.
Users aren't that needy yet, they just want to get access to their content in a reasonable delay, and they want the actions they make to register at most a few seconds after they submitted them, otherwise they'll start worrying about whether it successfully went through.
The Web is soft real time because taking longer to perform an operation would be seen as bad quality of service.
Erlang is a soft real time system. It will always run processes fairly, a little at a time, switching to another process after a while and preventing a single process to steal resources from all others. This means that Erlang can guarantee stable low latency of operations.
Erlang provides the guarantees that the soft real time Web requires.
The Web is asynchronous
Long ago, the Web was synchronous because HTTP was synchronous. You fired a request, and then waited for a response. Not anymore. It all began when XmlHttpRequest started being used. It allowed the client to perform asynchronous calls to the server.
Then Websocket appeared and allowed both the server and the client to send data to the other endpoint completely asynchronously. The data is contained within frames and no response is necessary.
Erlang processes work the same. They send each other data contained within messages and then continue running without needing a response. They tend to spend most of their time inactive, waiting for a new message, and the Erlang VM happily activate them when one is received.
It is therefore quite easy to imagine Erlang being good at receiving Websocket frames, which may come in at unpredictable times, pass the data to the responsible processes which are always ready waiting for new messages, and perform the operations required by only activating the required parts of the system.
The more recent Web technologies, like Websocket of course, but also HTTP/2.0, are all fully asynchronous protocols. The concept of requests and responses is retained of course, but anything could be sent in between, by both the client or the browser, and the responses could also be received in a completely different order.
Erlang is by nature asynchronous and really good at it thanks to the great engineering that has been done in the VM over the years. It's only natural that it's so good at dealing with the asynchronous Web.
The Web is omnipresent
The Web has taken a very important part of our lives. We're connected at all times, when we're on our phone, using our computer, passing time using a tablet while in the bathroom... And this isn't going to slow down, every single device at home or on us will be connected.
All these devices are always connected. And with the number of alternatives to give you access to the content you seek, users tend to not stick around when problems arise. Users today want their applications to be always available and if it's having too many issues they just move on.
Despite this, when developers choose a product to use for building web applications, their only concern seems to be "Is it fast?", and they look around for synthetic benchmarks showing which one is the fastest at sending "Hello world" with only a handful concurrent connections. Web benchmarks haven't been representative of reality in a long time, and are drifting further away as time goes on.
What developers should really ask themselves is "Can I service all my users with no interruption?" and they'd find that they have two choices. They can either hope for the best, or they can use Erlang.
Erlang is built for fault tolerance. When writing code in any other language, you have to check all the return values and act accordingly to avoid any unforeseen issues. If you're lucky, you won't miss anything important. When writing Erlang code, you can just check the success condition and ignore all errors. If an error happens, the Erlang process crashes and is then restarted by a special process called a supervisor.
Erlang developers thus have no need to fear unhandled errors, and can focus on handling only the errors that should give some feedback to the user and let the system take care of the rest. This also has the advantage of allowing them to write a lot less code, and let them sleep at night.
Erlang's fault tolerance oriented design is the first piece of what makes it the best choice for the omnipresent, always available Web.
The second piece is Erlang's built-in distribution. Distribution is a key part of building a fault tolerant system, because it allows you to handle bigger failures, like a whole server going down, or even a data center entirely.
Fault tolerance and distribution are important today, and will be vital in the future of the Web. Erlang is ready.
Learn Erlang
If you are new to Erlang, you may want to grab a book or two to get started. Those are my recommendations as the author of Cowboy.
The Erlanger Playbook The Erlanger Playbook is an ebook I am currently writing, which covers a number of different topics from code to documentation to testing Erlang applications. It also has an Erlang section where it covers directly the building blocks and patterns, rather than details like the syntax.
You can most likely read it as a complete beginner, but you will need a companion book to make the most of it. Buy it from the Nine Nines website.
Programming Erlang
This book is from one of the creator of Erlang, Joe Armstrong. It provides a very good explanation of what Erlang is and why it is so. It serves as a very good introduction to the language and platform.
The book is Programming Erlang, and it also features a chapter on Cowboy.
- Learn You Some Erlang for Great Good!
- LYSE is a much more complete book covering many aspects of Erlang, while also providing stories and humor. Be warned: it's pretty verbose. It comes with a free online version and a more refined paper and ebook version.
Introduction
Cowboy is a small, fast and modern HTTP server for Erlang/OTP.
Cowboy aims to provide a complete modern Web stack. This includes HTTP/1.1, HTTP/2, Websocket, Server-Sent Events and Webmachine-based REST.
Cowboy comes with functions for introspection and tracing, enabling developers to know precisely what is happening at any time. Its modular design also easily enable developers to add instrumentation.
Cowboy is a high quality project. It has a small code base, is very efficient (both in latency and memory use) and can easily be embedded in another application.
Cowboy is clean Erlang code. It includes hundreds of tests and its code is fully compliant with the Dialyzer. It is also well documented and features a Function Reference, a User Guide and numerous Tutorials.
Prerequisites
Beginner Erlang knowledge is recommended for reading this guide.
Knowledge of the HTTP protocol is recommended but not required, as it will be detailed throughout the guide.
Supported platforms
Cowboy is tested and supported on Linux, FreeBSD, Windows and OSX.
Cowboy has been reported to work on other platforms, but we make no guarantee that the experience will be safe and smooth. You are advised to perform the necessary testing and security audits prior to deploying on other platforms.
Cowboy is developed for Erlang/OTP 22.0 and newer.
License
Cowboy uses the ISC License.
Copyright (c) 2011-2019, Loïc Hoguin <essen@ninenines.eu>
Permission to use, copy, modify, and/or distribute this software for any purpose with or without fee is hereby granted, provided that the above copyright notice and this permission notice appear in all copies.
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
Versioning
Cowboy uses Semantic Versioning 2.0.0.
Conventions
In the HTTP protocol, the method name is case sensitive. All standard method names are uppercase.
Header names are case insensitive. When using HTTP/1.1, Cowboy converts all the request header names to lowercase. HTTP/2 requires clients to send them as lowercase. Any other header name is expected to be provided lowercased, including when querying information about the request or when sending responses.
The same applies to any other case insensitive value.
Getting started
Erlang is more than a language, it is also an operating system for your applications. Erlang developers rarely write standalone modules, they write libraries or applications, and then bundle those into what is called a release. A release contains the Erlang VM plus all applications required to run the node, so it can be pushed to production directly.
This chapter walks you through all the steps of setting up Cowboy, writing your first application and generating your first release. At the end of this chapter you should know everything you need to push your first Cowboy application to production.
Prerequisites
We are going to use the Erlang.mk build system. If you are using Windows, please check the Installation instructions to get your environment setup before you continue.
Bootstrap
First, let's create the directory for our application.
$ mkdir hello_erlang $ cd hello_erlang
Then we need to download Erlang.mk. Either use the following command or download it manually.
$ wget https://erlang.mk/erlang.mk
We can now bootstrap our application. Since we are going to generate a release, we will also bootstrap it at the same time.
$ make -f erlang.mk bootstrap bootstrap-rel
This creates a Makefile, a base application, and the release files necessary for creating the release. We can already build and start this release.
$ make run ... (hello_erlang@127.0.0.1)1>
Entering the command i(). will show the running processes, including one called hello_erlang_sup. This is the supervisor for our application.
The release currently does nothing. In the rest of this chapter we will add Cowboy as a dependency and write a simple "Hello world!" handler.
Cowboy setup
We will modify the Makefile to tell the build system it needs to fetch and compile Cowboy:
PROJECT = hello_erlang DEPS = cowboy dep_cowboy_commit = 2.8.0 DEP_PLUGINS = cowboy include erlang.mk
The DEP_PLUGINS line tells the build system to load the plugins Cowboy provides. These include predefined templates that we will use soon.
If you do make run now, Cowboy will be included in the release and started automatically. This is not enough however, as Cowboy doesn't do anything by default. We still need to tell Cowboy to listen for connections.
Listening for connections
First we define the routes that Cowboy will use to map requests to handler modules, and then we start the listener. This is best done at application startup.
Open the src/hello_erlang_app.erl file and add the necessary code to the start/2 function to make it look like this:
start(_Type, _Args) ->
Dispatch = cowboy_router:compile([
{'_', [{"/", hello_handler, []}]}
]),
{ok, _} = cowboy:start_clear(my_http_listener,
[{port, 8080}],
#{env => #{dispatch => Dispatch}}
),
hello_erlang_sup:start_link().
Routes are explained in details in the Routing chapter. For this tutorial we map the path / to the handler module hello_handler. This module doesn't exist yet.
Build and start the release, then open http://localhost:8080 in your browser. You will get a 500 error because the module is missing. Any other URL, like http://localhost:8080/test, will result in a 404 error.
Handling requests
Cowboy features different kinds of handlers, including REST and Websocket handlers. For this tutorial we will use a plain HTTP handler.
Generate a handler from a template:
$ make new t=cowboy.http n=hello_handler</code>
Then, open the src/hello_handler.erl file and modify the init/2 function like this to send a reply.
init(Req0, State) ->
Req = cowboy_req:reply(200,
#{<<"content-type">> => <<"text/plain">>},
<<"Hello Erlang!">>,
Req0),
{ok, Req, State}.
What the above code does is send a 200 OK reply, with the Content-type header set to text/plain and the response body set to Hello Erlang!.
If you run the release and open http://localhost:8080 in your browser, you should get a nice Hello Erlang! displayed!
Flow diagram
Cowboy is a lightweight HTTP server with support for HTTP/1.1, HTTP/2 and Websocket.
It is built on top of Ranch. Please see the Ranch guide for more information about how the network connections are handled.
Overview
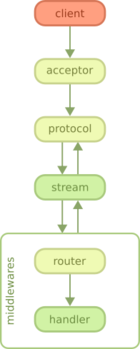
As you can see on the diagram, the client begins by connecting to the server. This step is handled by a Ranch acceptor, which is a process dedicated to accepting new connections.
After Ranch accepts a new connection, whether it is an HTTP/1.1 or HTTP/2 connection, Cowboy starts receiving requests and handling them.
In HTTP/1.1 all requests come sequentially. In HTTP/2 the requests may arrive and be processed concurrently.
When a request comes in, Cowboy creates a stream, which is a set of request/response and all the events associated with them. The protocol code in Cowboy defers the handling of these streams to stream handler modules. When you configure Cowboy you may define one or more module that will receive all events associated with a stream, including the request, response, bodies, Erlang messages and more.
By default Cowboy comes configured with a stream handler called cowboy_stream_h. This stream handler will create a new process for every request coming in, and then communicate with this process to read the body or send a response back. The request process executes middlewares which, by default, including the router and then the execution of handlers. Like stream handlers, middlewares may also be customized.
A response may be sent at almost any point in this diagram. If the response must be sent before the stream is initialized (because an error occurred early, for example) then stream handlers receive a special event indicating this error.
Protocol-specific headers
Cowboy takes care of protocol-specific headers and prevents you from sending them manually. For HTTP/1.1 this includes the transfer-encoding and connection headers. For HTTP/2 this includes the colon headers like :status.
Cowboy will also remove protocol-specific headers from requests before passing them to stream handlers. Cowboy tries to hide the implementation details of all protocols as well as possible.
Number of processes per connection
By default, Cowboy will use one process per connection, plus one process per set of request/response (called a stream, internally).
The reason it creates a new process for every request is due to the requirements of HTTP/2 where requests are executed concurrently and independently from the connection. The frames from the different requests end up interleaved on the single TCP connection.
The request processes are never reused. There is therefore no need to perform any cleanup after the response has been sent. The process will terminate and Erlang/OTP will reclaim all memory at once.
Cowboy ultimately does not require more than one process per connection. It is possible to interact with the connection directly from a stream handler, a low level interface to Cowboy. They are executed from within the connection process, and can handle the incoming requests and send responses. This is however not recommended in normal circumstances, as a stream handler taking too long to execute could have a negative impact on concurrent requests or the state of the connection itself.
Date header
Because querying for the current date and time can be expensive, Cowboy generates one Date header value every second, shares it to all other processes, which then simply copy it in the response. This allows compliance with HTTP/1.1 with no actual performance loss.
Binaries
Cowboy makes extensive use of binaries.
Binaries are more efficient than lists for representing strings because they take less memory space. Processing performance can vary depending on the operation. Binaries are known for generally getting a great boost if the code is compiled natively. Please see the HiPE documentation for more details.
Binaries may end up being shared between processes. This can lead to some large memory usage when one process keeps the binary data around forever without freeing it. If you see some weird memory usage in your application, this might be the cause.
Configuration
Listeners
A listener is a set of processes that listens on a port for new connections. Incoming connections get handled by Cowboy. Depending on the connection handshake, one or another protocol may be used.
This chapter is specific to Cowboy. Please refer to the Ranch User Guide for more information about listeners.
Cowboy provides two types of listeners: one listening for clear TCP connections, and one listening for secure TLS connections. Both of them support the HTTP/1.1 and HTTP/2 protocols.
Clear TCP listener
The clear TCP listener will accept connections on the given port. A typical HTTP server would listen on port 80. Port 80 requires special permissions on most platforms however so a common alternative is port 8080.
The following snippet starts listening for connections on port 8080:
start(_Type, _Args) ->
Dispatch = cowboy_router:compile([
{'_', [{"/", hello_handler, []}]}
]),
{ok, _} = cowboy:start_clear(my_http_listener,
[{port, 8080}],
#{env => #{dispatch => Dispatch}}
),
hello_erlang_sup:start_link().
The Getting Started chapter uses a clear TCP listener.
Clients connecting to Cowboy on the clear listener port are expected to use either HTTP/1.1 or HTTP/2.
Cowboy supports both methods of initiating a clear HTTP/2 connection: through the Upgrade mechanism (RFC 7540 3.2) or by sending the preface directly (RFC 7540 3.4).
Compatibility with HTTP/1.0 is provided by Cowboy's HTTP/1.1 implementation.
Secure TLS listener
The secure TLS listener will accept connections on the given port. A typical HTTPS server would listen on port 443. Port 443 requires special permissions on most platforms however so a common alternative is port 8443.
The function provided by Cowboy will ensure that the TLS options given are following the HTTP/2 RFC with regards to security. For example some TLS extensions or ciphers may be disabled. This also applies to HTTP/1.1 connections on this listener. If this is not desirable, Ranch can be used directly to set up a custom listener.
start(_Type, _Args) ->
Dispatch = cowboy_router:compile([
{'_', [{"/", hello_handler, []}]}
]),
{ok, _} = cowboy:start_tls(my_https_listener,
[
{port, 8443},
{certfile, "/path/to/certfile"},
{keyfile, "/path/to/keyfile"}
],
#{env => #{dispatch => Dispatch}}
),
hello_erlang_sup:start_link().
Clients connecting to Cowboy on the secure listener are expected to use the ALPN TLS extension to indicate what protocols they understand. Cowboy always prefers HTTP/2 over HTTP/1.1 when both are supported. When neither are supported by the client, or when the ALPN extension was missing, Cowboy expects HTTP/1.1 to be used.
Cowboy also advertises HTTP/2 support through the older NPN TLS extension for compatibility. Note however that this support will likely not be enabled by default when Cowboy 2.0 gets released.
Compatibility with HTTP/1.0 is provided by Cowboy's HTTP/1.1 implementation.
Stopping the listener
When starting listeners along with the application it is a good idea to also stop the listener when the application stops. This can be done by calling cowboy:stop_listener/1 in the application's stop function:
stop(_State) -> ok = cowboy:stop_listener(my_http_listener).
Protocol configuration
The HTTP/1.1 and HTTP/2 protocols share the same semantics; only their framing differs. The first is a text protocol and the second a binary protocol.
Cowboy doesn't separate the configuration for HTTP/1.1 and HTTP/2. Everything goes into the same map. Many options are shared.
Routing
Constraints
Handlers
Handlers
Loop handlers
Static files
Request and response
Request details
Reading the request body
Sending a response
Using cookies
Multipart
REST
REST principles
Handling REST requests
REST flowcharts
Designing a resource handler
Websocket
The Websocket protocol
Websocket handlers
Advanced
Streams
Middlewares
Performance
Additional information
Migrating from Cowboy 2.7 to 2.8
HTTP and other specifications